Course Name: Algorithmic Problem Solving
Course Code: 23ECSE309
Name: Akash Nayak
SRN: 01FE21BEC263
University: KLE Technological University, Hubballi-31
Portfolio domain: Youtube
Table of Contents
Introduction
YouTube is the world’s largest video-sharing platform and operates on a complex technological infrastructure. With over 2 billion monthly active users, more than 500 hours of videos are posted to YouTube every minute. Daily views of YouTube Shorts, a feature for short video content, are 15 billion. YouTube launched a $100 million Shorts Fund to entice Creators to experiment with producing short-form videos. Approximately 30,000 hours of video are uploaded to YouTube every hour by artists. Every week, 92% of internet users watch some form of YouTube video. YouTube also has the second-largest search engine in the world. Branded searches make up 52% of the top 100 queries. Leading countries based on YouTube audience size are the US, India, Japan, and Indonesia.
The smooth experience that users and creators enjoy is possible due to various data structures and algorithms working under the hood. These technologies ensure efficient data management, personalized recommendations, optimized streaming, and much more. This portfolio explores the critical role of various data structures and algorithms that can potentially enhance YouTube’s features and functionalities. By examining existing and potential use cases for these technologies, this portfolio aims to provide a comprehensive understanding of their impact on the platform.
Reference: Simplilearn. (2024). Top YouTube Marketing Stats You Should Know About in 2024. Online. Simplilearn. https://www.simplilearn.com/youtube-marketing-stats-article
Objectives
- Categorize features and underlying technologies of YouTube.
- Identify key algorithms, data structures, or system design techniques currently in use or with potential applications in enhancing YouTube’s features.
- Create a resource that can be used for educational purposes to understand the intersection of data structures, algorithms, and real-world applications in a large-scale platform like YouTube.
Journey of the content
Let’s explore the journey of a video from the creator to the viewer before we explore the business cases. There are three stakeholders in the content lifecycle: The Creators who record, edit, and upload videos; the YouTube platform where the video is uploaded and stored in the data centers; and finally, the Viewers who watch the video.
High level design of YouTube's Infrastructure
Initially, when the creator tries to upload a video to YouTube, the file is directed to Upload servers that facilitate uploading the file from the client’s device to a BLOB storage. After the video is uploaded and stored, they are fetched by the Transcoding server for processing and encoding the video to different bitrates and formats. The transcoded videos are distributed to Content Delivery Networks (CDNs) that are strategically and geographically placed. When the viewer starts streaming a video, they get the first segment of that video from the nearest CDN, and streaming protocols like MPEG-DASH help stream segments adaptively based on the viewer’s network bandwidth [1].
Business Use Cases
1. Video Transcoding
YouTube handles more than 500 hours of video data being uploaded every minute. The time for processing these videos will significantly impact the latency and user experience. Transcoding is a computationally intensive operation done only once while uploading the videos. Compression algorithms like HEVC (High-Efficiency Video Coding) can be used here to compress the video into multiple formats and resolutions. Huffman coding [2] algorithm can be potentially used for compressing a significant amount of metadata like video duration, title, description, tags, subtitles, thumbnails, etc. The uploaded video can be separated into video and audio components and algorithms like AAC (Advanced Audio Codec) can be used to convert audio into multiple formats and bitrates [3].
Challenges: Handling large video data, Efficient and fast video processing.
Market Benefits: Efficient data storage and continuous playback on all devices.
Design techniques and algorithms:
- Huffman coding: Greedy technique
- Time Complexity: O(nlog(n)) where n is number of unique characters.
- Space Complexity: Linear [O(n)], for storing Huffman tree and encoded data.
View Implementation: Huffman Coding
2. Directed Acyclic Graph (DAG) for transcoding pipeline
Different creators have different video processing requirements. Some might add a custom thumbnail, watermarks, or upload a high-definition video whereas others do not. To support these processing pipelines and maintain parallelism a DAG model can be used which defines tasks in stages so that they can be executed parallelly or sequentially [1]. These tasks can be scheduled using the Topological sort.
Example for a Directed Acyclic Graph with stages.
A resource manager can be used for managing the efficiency of resource allocation. It needs to have 3 queues: the “Task queue” which is a priority queue that contains the tasks to be executed; the “Worker queue” which is also a priority queue that contains information about worker utilization; and the “Running queue” that includes information on currently running tasks and workers [1]. The task scheduler picks the highest priority task and the most optimal worker.
The Resource manager used in the pipeline [1].
Challenges: Allocation of available resources.
Market Benefits: Efficient resource management, Minimized cost.
Design techniques and algorithms:
- Topological Sort for DAGs: DFS based solution
- Time Complexity: O(V+E) where V represents several tasks and E represents the dependencies/ edges of DAG.
- Space Complexity: O(V). The extra space is needed for the stack.
- Priority queues Min/Max heap, C++ std::priority_queue
- Time Complexity: O(logN) for insertion and deletion (push and pop)
- Space Complexity: O(N)
View Implementation: Topological Sort, Priority Queue
3. Routing the data
The data packets of the video need to flow through several nodes including servers, data centers, CDNs, and several network core components before they reach the viewer’s device. To find the most optimal path to route the data, the network can be abstracted as a graph where each node represents a network device, and an edge between two connected devices represents the link with a cost associated with it. The link-cos (edge weight) can be decided based on various factors like bandwidth, financial costs, congestion, etc. Dijkstra’s algorithm [4] can be used here to find the shortest path from a source node to all other nodes on the network, minimizing latency at all stages by avoiding congested routes. If the network topology is fairly stable, the Floyd-Warshall algorithm can also be used to create a matrix of shortest path (for all node pairs) as a pre-compute for faster lookups in routing [5].
Dijkstra's algorithm is used to calculate the shortest path for routing data.[9].
Challenges: High traffic, Fluctuating network conditions.
Market Benefits: Reduced latency, Cost savings.
Design techniques and algorithms:
- Dijkstra’s Algorithm: Priority queue
- Time Complexity: O((V+E)logV) where V represents several vertices/nodes and E represents the edges/links of the graphs.
- Space Complexity: O(V) for storing distances.
- Floyd Warshall Dynamic programming approach
- Time Complexity: O(V^3) where V is the number of vertices in the graph.
- Space Complexity: O(V^2), to create a 2-D matrix that stores the shortest distance for each pair of nodes.
View Implementation: Dijkstra’s Algorithm, Floyd Warshall’s Algorithm
4. Streaming optimization
The CDN has cached versions of the transcoded videos based on regional popularity. This is the reason why less popular videos take more time to load as compared to popular ones they are not streamed from the CDN. Videos are streamed from CDN directly. The edge server closest to you will deliver the video. Partnering with ISPs might help improve viewer experience and reduce bandwidth charges. An A* search [6] can be used to find the most efficient path for content delivery through a network of servers, where the “heuristics” can consider server load and geographical closeness. A best-first search can also be used for the same purpose. [7]
A* algorithm example of calculating the shortest path based on heuristics [10].
Challenges: CDN costs, Smooth playback for all users.
Market Benefits: Reduced latency, Cost savings, Smoother playback.
Design techniques and algorithms:
- A * Search Algorithm: Greedy approach, heuristic based
- Time Complexity: depends on the quality of the heuristic function but in worst case O(E), where E is the number of edges in the graph.
- Space Complexity: O(V) auxiliary space in worst case.
- Best first search Priority queue, BFS
- Time Complexity: O(N * log N) , where N is number of nodes.
- Space Complexity: O(N) auxiliary space in worst case.
View Implementation: A* Search Algorithm, Detailed A*, Best first search
5. Video Recommendations
Viewers interact with videos in many ways like linking, commenting, sharing, and watching a certain type of content for longer hours. A viewer’s watch history. Liking and preferences can be used to recommend similar videos to the user. Item-based collaborative filtering algorithms can be used to recommend videos identical to the ones the viewer has watched. A user-item interaction matrix can be created and similarity is calculated using cosine similarity. The most similar items for the target are selected for recommendation. ALS (Alternating Least Squares) algorithm is another algorithm used in collaborative filtering that can find relations between users and videos [8].
Collaborative and Content based filtering [11].
Challenges: Real-time processing, Data overload.
Market Benefits: Personalization, increased user satisfaction.
Design techniques and algorithms:
- Collaborative filtering: ALS Algorithm Item-based filtering
- Time Complexity: O(U*I^2) where U and I represent the total number of Users and Items.
- Space Complexity: O(U*I) for the 2D matrix
View Implementation: Collaborative Filtering
6. Autocompletion of search query
The viewers can sometimes search for longer titles in the search bar. Autocompleting the next possible word might help enhance the user experience. As the user starts typing in a word, the completion for that word can be provided using tries. The Trie Data Structure is used here to suggest words based on prefixes [12]. NLP techniques can also be applied for accurate autocompletion.
Working for Autocomplete feature
Example for how Trie suggests the words "Amazon" and "Amazing" based on the prefix "AMAZ" [12].
Challenges: Real-time correction, predicting user’s intent, personalization.
Market Benefits: Improved user experience and increased user retention rates.
Design techniques and algorithms:
- Trie Data Structure Greedy approach, heuristic-based
- Time Complexity: O(K) for insertion and searching where K is the length of the string.
- Space Complexity: O(N*avgK) where N is the number of words and avgK is the average length of the words.
View Implementation: Tries
7. Managing Traffic
YouTube serves videos for about 122 million users per day. That’s a huge amount of video requests, especially during viral events like a stream of the 2024 World Cup parade in Mumbai. To optimize the network resource utilization, Max flow algorithms [13] like Ford-Fulkerson can help assist load balancing across servers and minimize network congestion. The network is abstracted as a graph with capacities assigned to the edges. The Max flow algorithm finds the optimal flow path that maximizes throughput at minimum cost. However, the capacities need to be updated dynamically (real-time).
Challenges: Load balancing millions of requests, Dynamic updates.
Market Benefits: Scalability, Cost savings, Low latency.
Design techniques and algorithms:
- Max Flow algorithm - Ford Fulkerson BFS
- Time Complexity: O(V*E^2) where E is the number of edges and V is the number of vertices of the graph.
- Space Complexity: O(V) for queue.
View Implementation: Max Flow- Ford Fulkerson
8. Autocorrect search query
The viewers can search for their favorite videos using the search bar. Autocorrecting the misspelled words can increase the search accuracy. A Trie data structure can be used to correct misspelled words by providing the closest match. A dictionary of words is stored in the trie and as the user types, matching words can be suggested based on the entered prefix/word.
Working of Autocorrect in searches
Challenges: Real-time correction, predicting user’s intent.
Market Benefits: Improved user experience and increased user retention rates.
Design techniques and algorithms:
- Trie Data Structure Greedy approach, heuristic-based
- Time Complexity: O(K) for insertion and searching where K is the length of the string.
- Space Complexity: O(N*avgK) where N is the number of words and avgK is the average length of the words.
View Implementation: Tries
9. Personalized playlist
YouTube creates a personalized playlist of the most viewed videos and the videos similar to it. It also recommends videos when you watch a series of videos, for example, if a user is watching “Gate smashers - Operating Systems Part 1”, the next parts will be recommended as a “Mix” playlist. However, recommending part 3 after part 1 is not ideal. Topological sort can be used here if every video of the playlist is treated as a node of a DAG (Directed Acyclic Graph) with directed edges between two videos to represent the dependencies. The topological sort algorithm will arrange the videos in a linear order.
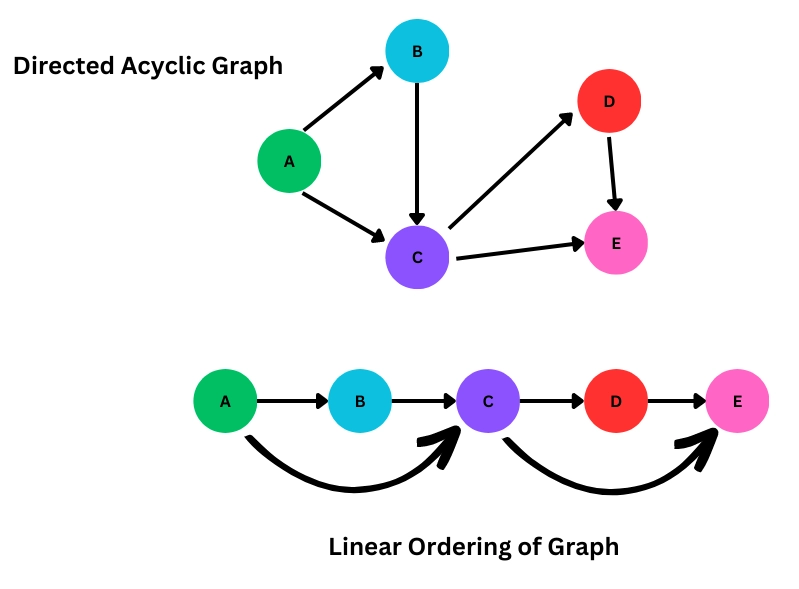
Topological sort working on DAGs. [13]
Challenges: Additional processing, manual curation of metadata, support for new videos added.
Market Benefits: Enhanced flexibility in watching videos.
Design techniques and algorithms:
- Topological Sort for DAGs: DFS based solution
- Time Complexity: O(V+E) where V represents several tasks and E represents the dependencies/ edges of DAG.
- Space Complexity: O(V). The extra space is needed for the stack.
View Implementation: Topological Sort
10. Content Monitoring
With billions of users on the platform of all age groups, it becomes important to block harmful content and hate speech in the content. This can include explicit speech in comments or the video. Pattern searching algorithms like Rabin-Karp [15] can be used to detect such words from a wordlist and remove the content or the account associated with it if several strikes on the account increase the threshold. The audio from the video can be transcribed or subtitles can be used to detect the explicit words. The comment check can be handled in both the front end and back end.
Pattern Searching example [15]
Challenges: False positives during processing, Additional processing.
Market Benefits: Enhanced safety of the platform and protection of viewers.
Design techniques and algorithms:
- Pattern Searching Algorithm - Rabin-Karp: Hashing-based
- Time Complexity: O(N+M) where N is the length of text/string, and M is the length of the pattern (explicit word).
- Space Complexity: O(1) Auxiliary Space
View Implementation: String matching: Rabin-karp
11. User activity tracking
YouTube monitors user data (metrics) like time spent watching videos, number of interactions on videos, and likes and dislikes. A segment tree or a Fenwick tree can be created where nodes store either watch time or count of interactions over a specific period for a specific user. Operations like Range sum queries and Range updates can be utilized to analyze the data.
Challenges: Dynamically updating the data.
Market Benefits: Better understanding of user activity on the platform.
Design techniques and algorithms:
- Segment Tree for handling queries: Array implementation
- Time Complexity: O(NlogN) for construction, O(logN) for query and update where N is the number of nodes.
- Space Complexity: O(N)
- Fenwick Tree Array implementation
- Time Complexity: O(NlogN) for construction, O(logN) for query and update where N is the number of nodes.
- Space Complexity: O(N)
View Implementation: Segment Tree, Fenwick Tree
12. Consistent hashing in CDNs
CDNs are often implemented as a cluster of servers that are geographically located closer to users. There are several strategies for distributing the incoming requests to large groups of servers. A scalable design technique is Consistent Hashing. When a request for video arrives at a CDN, a hash function is applied to its identifier (URL or ID) which outputs a numerical value. The numerical value is mapped onto a hashring which represents user requests and server nodes as a virtual ring. The video request is directed to a server that is closest to the request (Clockwise) on the ring [16].
A CDN Hash Ring consisting of Severs and Request for documents (video, images, etc). [16]
Challenges: Handling node failures and managing Dynamic content like live streams.
Market Benefits: Improved scalability, Reduced latency, and downtime.
Design techniques and algorithms:
- Consistent hashing Sample implementation using a simple hash function and binary search to find position.
- Time Complexity: O(logN), where N is number of nodes.
- Space Complexity: O(R*N) where R is number of replicas.
View Implementation: Simple Consistent Hashing Example
13. Efficient Data Storage in CDNs - Caching
CDNs need to cache the data for the most popular content in a particular region. This includes data like HTML documents, stylesheets, JavaScript files, transcoded video segments, metadata, etc. There are several cache replacement algorithms for maintaining the cached data in a CDN server. A Least Recently Used (LRU) cache replacement algorithm can be used to remove the data that is least recently used from the memory [17].
A CDN Caching documents with LRU eviction policy (HTML, JS, compressed video segments, etc) [17]
Challenges: Cache invalidation, Cache consistency.
Market Benefits: Improved scalability and lower bandwidth costs.
Design techniques and algorithms:
- Least Recently Used Cache Replacement Queue and Hashing approach
- Time Complexity: O(1) for put and get calls.
- Space Complexity: O(N) where N is capacity of the cache.
View Implementation: Simple LRU cache example
14. Efficient Data Storage in CDNs - Compression
As CDN servers store data like HTML documents, stylesheets, JavaScript files, transcoded video segments, metadata, etc. it is important to compress it for efficient storage and faster data transmission rates. The most used algorithms are Gzip which combines LZ77 and Huffman coding.
Challenges: Balancing compression ratio and computing costs.
Market Benefits: Cost reduction and Scalablity.
Design techniques and algorithms:
- Huffman coding: Greedy technique
- Time Complexity: O(nlog(n)) where n is number of unique characters.
- Space Complexity: Linear [O(n)], for storing Huffman tree and encoded data.
View Implementation: Huffman Coding
15. Load Balancing Requests
YouTube handles a huge traffic of video requests using a network of CDNs. These CDNs do the task of load balancing. They direct user requests to the server with minimal resource usage like CPU, memory, and bandwidth. This is very crucial when popular videos are being watched by millions of users. All these servers in the CDN cluster don’t necessarily have the same resources like RAM and memory. Hence, it is important to handle incoming requests and direct them to a server that can process them efficiently. Load balancing algorithms like Round Robin and Weighted Round Robin help to direct requests to the server based on their metrics (Health metrics). These algorithms can be static or dynamic like the Least connection method [19].
An overview of how load balancing works [18]
Challenges: Detecting and handling dynamic traffic patterns and efficient resource utilization.
Market Benefits: Scalablity, and Availablity due to reduced chances of server overload.
Design techniques and algorithms:
- Round Robin Load Balancing: Static, Greedy approach
- Time Complexity: O(1) if number of servers are static.
- Space Complexity: O(N) where N represents number of servers.
- Weighted Round Robin Load Balancing: Static, Greedy approach
- Time Complexity: O(1) if number of servers are static.
- Space Complexity: O(N) where N represents number of servers.
View Implementation: Round Robin, Weighted Round Robin
Learnings
Building an application for billions of users requires carefully planned system design to provide users with a better experience and ensure the smooth functioning of the application at all times. Through the exploration of various algorithms discussed in this portfolio for various business cases, it is clear that data structures and algorithms have a huge impact on addressing real-world problems and pushing out new features in applications. Data structures are the building blocks upon which efficient algorithms can be designed and used in a high-performance system. With a huge amount of dynamic data coming in, algorithms make it easy to organize and manage it. Algorithms are always evolving, and with researchers continuously exploring smarter ways of solving a problem, large-scale companies need to be on the lookout for exploring them for a specific business case. My personal experience in building this portfolio provided me with an understanding of the bigger picture of how things work at scale and algorithms working under the hood making it look effortless. This portfolio project is a resource for individuals with a curiosity about using algorithms to solve real-world problems.
References
[1] ByteByteGo. (2023). “System Design Interview - Design YouTube”. Online. ByteByteGo. https://bytebytego.com/courses/system-design-interview/design-youtube
[2] Dremio. (2024). “Huffman Coding”. Online. Dreamio. https://www.dremio.com/wiki/huffman-coding/
[3] Jonny E. (2023). “ What Is Video Transcoding?”. Online. Massiveio. https://massive.io/file-transfer/what-is-video-transcoding/
[4] Wikipedia. (2024). “Dijkstra’s Algorithm”. Online. Wikipedia. https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm
[5] GeeksForGeeks. (2024). “Shortest Path Algorithm in Computer Network”. Online. GeeksForGeeks. https://www.geeksforgeeks.org/shortest-path-algorithm-in-computer-network/
[6] Wikipedia. (2024). “A* Search Algorithm”. Online. Wikipedia. [https://en.wikipedia.org/wiki/A_search_algorithm](https://en.wikipedia.org/wiki/A_search_algorithm)
[7] GeeksForGeeks. (2023). “Best First Search (Informed Search)”. Online. GeeksForGeeks. https://www.geeksforgeeks.org/best-first-search-informed-search/
[8] Sophie. (2018). “A gentle introduction to Alternating Least Squares”. Online. Github. https://sophwats.github.io/2018-04-05-gentle-als.html
[9] Mohit J. (2021). “How OSPF Protocol implements Dijkstra’s Algorithm”. Online. Medium. https://mohitjangir700.medium.com/how-ospf-protocol-implements-dijkstras-algorithm-7cf701811215
[10] GeeksForGeeks. (2024). “A* Search Algorithm”. Online. GeeksForGeeks. https://www.geeksforgeeks.org/a-search-algorithm/ [11] Abhijeet A. (2020). “User-User Collaborative Filtering For Jokes Recommendation”. Online. TowardsDataScience. https://towardsdatascience.com/user-user-collaborative-filtering-for-jokes-recommendation-b6b1e4ec8642
[12] Vivien L. (2024). “Autocomplete with trie (3 solutions) – Code”. Online. Lavivienpost. https://www.lavivienpost.com/autocomplete-with-trie-code/
[13] GeeksForGeeks. (2024). “Ford-Fulkerson Algorithm for Maximum Flow Problem”. Online. GeeksForGeeks. https://www.geeksforgeeks.org/ford-fulkerson-algorithm-for-maximum-flow-problem/
[14] Ravi K. (2024). “Topological Sorting”. Online. Naukri. https://www.naukri.com/code360/library/topological-sorting
[15] GeeksForGeeks. (2024). “Introduction to Pattern Searching”. Online. GeeksForGeeks. https://www.geeksforgeeks.org/introduction-to-pattern-searching/
[16] Tim S. (2020). “ The Algorithm Series: The Math Behind the CDN”. Online. Streamingmedia. https://www.streamingmedia.com/Articles/Editorial/Featured-Articles/The-Algorithm-Series-The-Math-Behind-the-CDN-136194.aspx?pageNum=2
[17] Hayk S. (2024). “The Ultimate Guide to Caching and CDNs”. Online. Medium. https://hayk-simonyan.medium.com/the-ultimate-guide-to-caching-and-cdns-80e0d773e624
[18] PsychzNetworks. (2020). “CDN and Load Balancer: Ultimate combination for efficient content delivery”. Online. PsychzNetworks. https://www.psychz.net/client/blog/en/cdn-and-load-balancer-ultimate-combination-for-efficient-content-delivery-.html
[19] AWS. (2024). “What is Load Balancing?”. Online. Amazon. https://aws.amazon.com/what-is/load-balancing/